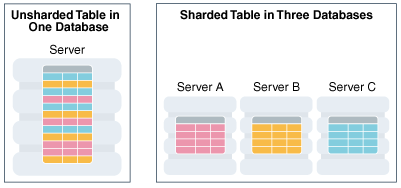
Phân chia dữ liệu (Sharding) là một giải pháp chia nhỏ một Database lớn thành nhiều Database nhỏ, ta có thể phân tách từng bảng hoặc cả một DB ra nhiều phần nhỏ đặt ở nhiều máy chủ (server) khác nhau. Điều này sẽ giúp cho hệ thống DB của chúng ta đạt được các tính chất khả năng bảo trì (manageability), hiệu xuất (performance), tính sẵn sàng (availability), và cân bằng tải (load balancing) của ứng dụng. Và giải pháp này cũng giảm chi phí cũng như tính mở rộng (scalability) để scale up DB bằng cách dùng nhiều server nhỏ gộp lại hơn là nâng cấp một server lớn.
NHỮNG CÁCH THỨC PHÂN CHIA DỮ LIỆU
Ta có 3 cách thức Sharding dữ liệu như sau:
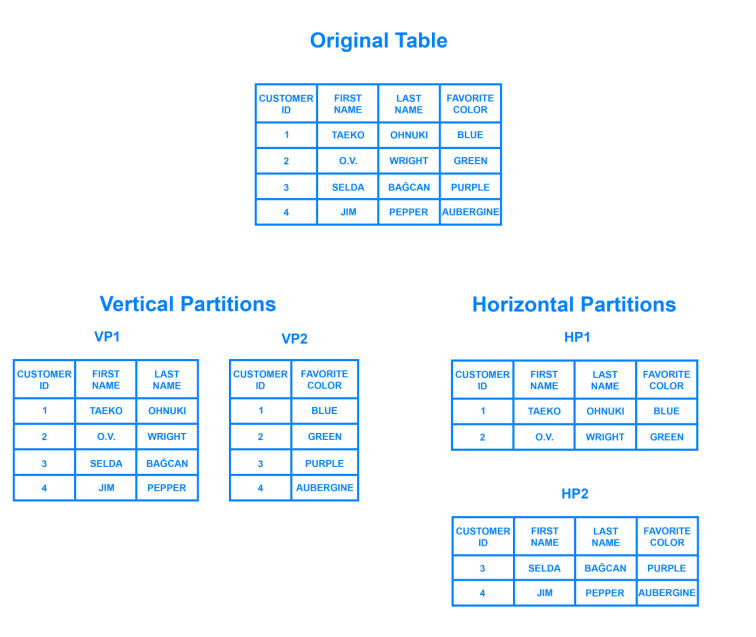
- Horizontal sharding
Là cách chia cùng dữ liệu của cùng một bảng (table) ra nhiều DB khác nhau. Ví dụ ta có bảng dữ liệu thông tin về người dùng, ta sẽ dựa trên location của người dùng để quyết định nó nằm ở DB nào, ví dụ người dùng ở Sài Gòn thì sẽ chứ ở DB_SG, thông tin người dùng ở Biên Hòa sẽ nằm ở DB_BH hay thông tin người dùng ở Vĩnh Long sẽ nằm ở DB_VL.
Giải pháp này có một vấn đề là ta phải chọn nơi dữ liệu Sharding rất cẩn thận để không gây mất cân bằng (unbalanced) giữa các DB dẫn tới rất có thể có một vài Server sẽ thành điểm nóng (hot spot), ví dụ người dùng ở Sài Gòn chắc chắn là đông hơn rất nhiều lần người dùng ở Biên Hòa hay Vĩnh Long. - Vertical sharing
Là cách sharding dữ liệu dựa trên tính năng (feature) của hệ thống. Ví dụ ta thiết kế một hệ thống chia sẻ ảnh giống Instagram, ta sẽ lưu thông tin của User vào DB_Users, lưu thông tin ảnh họ up lên trên một DB khác là DB_Photos và thông tin danh sách những người họ follow ở một DB thứ 3 là DB_Follow.
Cách làm này rất là rõ ràng dễ để implement và không làm ảnh hưởng lớn đến ứng dụng, nhưng khi hệ thống lớn dần lên thì dữ liệu cũng lớn dần theo, do đó ta lại phải thực hiện sharding tiếp những DB trên từng feature (bởi vì 1 DB không thể sử lý 10 tỷ bức ảnh của 140 triệu user được). - Directory Based sharding
Cách này sẽ yêu cầu ta phải thiết kế một “lookup service” có tác dụng quyết định ánh xạ (mapping) dữ liệu sẽ nằm ở đâu, DB nào. Mỗi khi có request ghi hoặc đọc sẽ thông qua lookup service để mapping vị trí sẽ đọc và ghi. Khi business mở rộng số lượng server có thể tăng lên mà không ảnh hưởng hay đòi hỏi ứng dụng phải thay đổi theo.
NHỮNG TIÊU CHÍ ĐỂ PHÂN VÙNG DỮ LIỆU
Bên trên ta đã tìm hiểu và các method để sharding dữ liệu, giờ ta hãy tìm kiểu sâu hơn về các tiêu chí để phân vùng dữ liệu.
- Phân vùng theo key hoặc hash
Hệ thống sẽ áp dụng các hàm băm (hash function) cho một hoặc nhiều các key chính trong dữ liệu (thường là ID) để xác định ra một con số của phân vùng nó đang nằm. Ví dụ: nếu hệ thống có 100 máy chủ DB và ID của bản ghi sẽ tự tăng lên mỗi lần một bản ghi mới được chèn. Trong ví dụ này, hàm băm có thể là ‘ID% 100, từ đó ta có thể xác định vị trí của dữ liệu. Cách tiếp cận này cần đảm bảo phân bổ dữ liệu thống nhất giữa các máy chủ. Nhưng cách làm này có một điểm yếu là mỗi khi ta thay đổi số lượng Server tăng hoặc giảm thì hàm băm cũng sẽ phải thay đổi theo và sẽ xuất hiện hiện tượng xáo trộn tập dữ liệu trên mỗi server, và đòi hỏi ta phải phân phối lại dữ liệu và xuất hiện độ trễ dữ liệu. Có một cách giải quyết vấn đề này là sử dụng Consistent Hashing (hàm băm nhất quán). - Phân vùng theo danh sách (list)
Cách phân vùng sẽ được quyết định gán một danh sách các giá trị ngay từ đầu, từ đó mỗi lần ghi một bản ghi mới ta sẽ tìm ra giá trị của bản ghi nằm ở phân vùng nào và ghi vào đó. Ví dụ ta sẽ quyết định nhóm tất cả các người dùng ở Ai-len, Na Uy, Thụy Điển, Phần Lan và Đan Mạch và một phân vùng có tên là Nordic (Bắc Âu). - Phân vùng vòng tròn (round-robin)
Cách phân vùng này rất đơn giản là mỗi lần có thao tác ghi ta sẽ ghi vòng tròn quanh các phân vùng có sẵn. Cách làm này đơn giản nhưng rất khó để xác định dữ liệu nào ở đâu lấy ra khi cần. - Phân vùng tổng hợp
Là cách tổng hợp các giải pháp trên thành một giải pháp mới. Ví dụ ta có thể áp dụng phân vùng theo Key/Hash và sau đó xác định được key rồi ta sẽ áp dụng tiếp phân vùng theo danh sách để chứa key sau khi hash vào một danh sách cụ thể nào đó. Consistent Hashing có thể được coi là cách phân vùng tổng hợp.

CÁC VẤN ĐỀ KHI SHARDING DỮ LIỆU
Vì việc dữ liệu sẽ bị phân tán đi nhiều Server khác nhau do vậy sẽ phát sinh một vài vấn đề khi sharding dữ liệu như sau:
- Joins and De-normalization
Bởi vì việc dữ liệu ở các bảng được phân bố và trải rộng đi nhiều DB/Server khác nhau nên việc join bảng dữ liệu là điều rất khó khăn và cũng không đem lại hiệu xuất bởi vì việc dữ liệu phải được queries từ nhiều máy chủ khác nhau. Để giải quyết vấn đề này ta có thể thiết kế dữ liệu dạng non-relationship DB hay còn gọi là NoSQL, giống như MongoDB hay Cassandra hai hệ NoSQL rất nổi tiếng và hỗ trợ Sharding vô cùng tốt. Tuy nhiên việc này ta phải chấp nhận rủi ro việc không nhất quán dữ liệu (inconsistency) - Referential integrity
Cũng vì lý do trên về việc truy vấn chéo dữ liệu giữa các DB nằm trên các máy chủ khác nhau là bất khả thi, do vậy việc ràng buộc khóa ngoại để bảo đảm sự toàn vẹn dữ liệu cũng là một điều vô cùng khó khăn. Hầu hết RDBMS không hỗ trợ các ràng buộc khóa ngoại trên các cơ sở dữ liệu phân tán trền nhiều server. Do vậy để đạt được điều này ta phải thực hiện điều này trên mã ứng dụng (code), điều này sẽ tăng tính phức tạp của ứng dụng. - Rebalancing
Trong suốt quá trình hệ thống vận hành có rất nhiều lý do ta thay đổi các chiến thuật hay cách thức Sharding dữ liệu, như business tăng trưởng yêu cầu thêm Server… Và mỗi khi như vậy ta phải tái cân bằng (rebalancing) dữ liệu trên tất cả các Server, có nghĩa là dữ liệu phải được phân phối lại trên toàn bộ server. Để làm được điều này mà không có độ trễ (downtime) là cực kỳ khó khăn. Mô hình sharding “Directory Based” có khả năng rebalancing tốt nhất nhưng lại tăng độ phức tạp của ứng dụng và tạo thêm một single point of failure (ví dụ “lookup service”).
Tóm lại với Sharding thì mô hình sharding với key/hash với Consistent Hashing hiện tại là giải pháp tối ưu nhất cho việc Rebalancing.
Tác giả: Edward Thiên Hoàng