Ngày nay với sự phát triển của các website thương mại điện tử, việc chú trọng đến trải nghiệm người dùng cũng như tiếp cận những sản phẩm đến tay người dùng vô cùng quan trọng. Hệ thống gợi ý sản phẩm ra đời để giúp người dùng có thể tìm thấy các sản phẩm mà họ mong đợi.
I. Hệ thống Recommender systems là gì ?
Nói một cách đơn giản recommender systems là hệ thống dựa vào “sở thích” của người dùng trong quá khứ, để dự đoán “sở thích” người dùng trong tương lai và thực hiện gợi ý cho người dùng. Để một hệ thống recommender systems hoạt động tốt điều tiên quyết là phụ thuộc vào sự phản hồi của người dùng. Các phản hồi này có thể là đánh giá sao, bình luận, số lần click chuột vào sản phẩm, thời gian quan sát sản phẩm,… Về cơ bản recommender systems được chia làm 3 công nghệ chính :
-
Collaborative filtering ( Lọc cộng tác )
-
Content-based filtering (Lọc theo nội dung)
-
Hybrid filtering ( Lọc hỗn hợp )
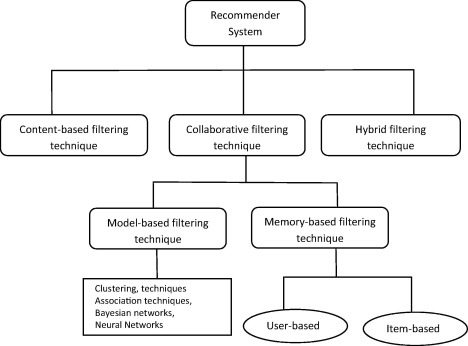
Trong khuôn khổ bài viết này mình sẽ hướng dẫn cho các bản triển khai 4 hệ thống gợi ý bao gồm : user-based, item-based, content-based và session-based.
II. Lọc công tác (Collaborative filtering) :
Ý tưởng của Lọc cộng tác: “người tương tự” có thể thích “sản phẩm tương tự” hoặc ngược lại, từ đó việc của chúng ta cần làm là tìm ra mối tương quan giữa các user và item để gợi ý các sản phẩm cho người dùng.
1. User-based :
User-base là một dạng recommender systems dựa vào độ tương quan giữa các user để gợi ý sản phẩm cho các user.
Đến đây các bạn sẽ có một câu hỏi : làm sao để tính độ tương quan của người dùng ?
Chúng ta sẽ tính độ tương quan của các user dựa vào khoảng cách giữa các user trong ma trận biểu diễn user - item. Nếu khoảng cách giữa 2 user càng nhỏ tức 2 user có độ tương tự như nhau và ngược lại.
Vậy chúng ta tính khoảng cách bằng gì? Tất nhiên là không phải bằng thước rồi :v. Chúng ta sẽ tính khoảng cách bằng các công thức Ơ-clit, Minkowski, Cosin,.. Trong bài này mình sẽ sử dụng công thức tính khoảng cách cosin.
Tuy không phải là người Hải Phòng nhưng mình cũng không thích lòng vòng. Mình triển khai ngay một hệ thống gợi ý sử dụng user-based để mọi người cùng hiểu nhé.
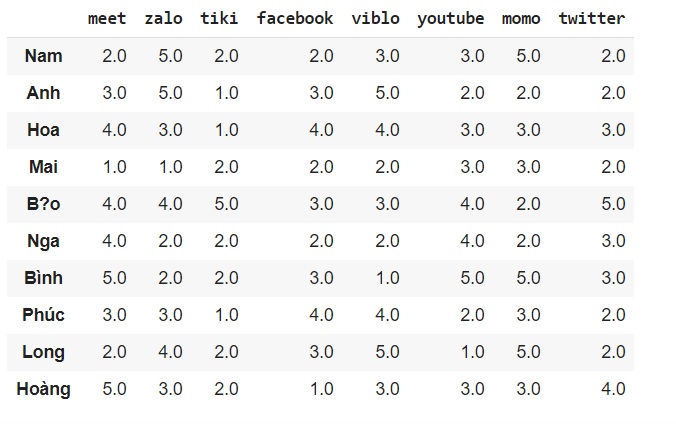
Ví dụ mình có một bảng dưới đây thể hiện sự rating sao của 10 người dùng cho 8 app trên điện thoại của họ( các ô trống là những ô người dùng không hoặc chưa đánh giá) từ đó chúng ta cần đưa ra dự đoán sự yêu thích của họ với các ô trống chưa được đánh giá để gợi ý cho người dùng. mọi người có thể tải data mẫu tại đây
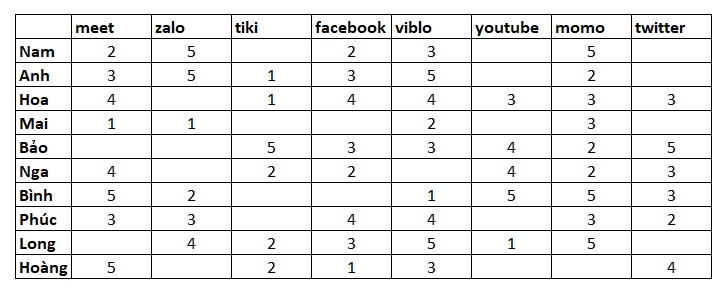
Mình sẽ sử dụng công thức cosin để tính độ tương quan của user :
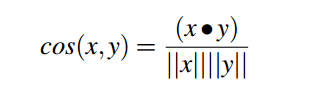
Đầu tiền mình sẽ import một số thư viện cần thiết cho bài toán :
import numpy as np from sklearn.metrics.pairwise import cosine_similarity import pandas as pd
Load dữ liệu và visualization dữ liệu bằng dataframe :
data = pd.read_csv('./data_collaborative.csv', sep=';') print(data)
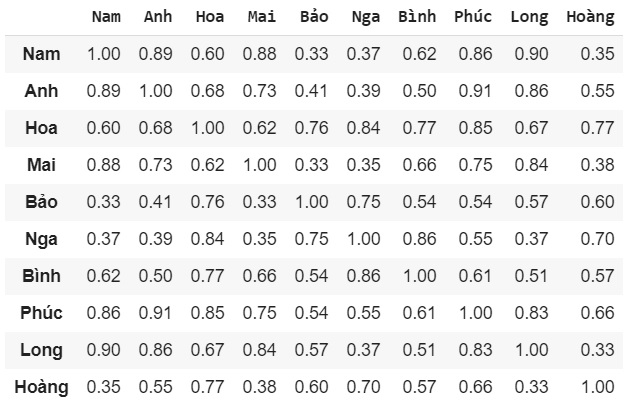
sử dụng hàm cosine_similarity trong thư viện sklearn để tính khoảng cách giữa các user
Sim = cosine_similarity(data_matrix,data_matrix) Sim = np.round(Sim, decimals = 2) Sim
Sau khi tính xong ta sẽ được ma trận khoảng cách giữa các user như hình:
Tiếp tục chúng ta sẽ dựa vào độ tương quan của các user để dự đoán các đánh giá các item mà user trước đó chưa đánh giá, mình sẽ áp dụng công thức dự đoán tại từng điểm dữ liệu :
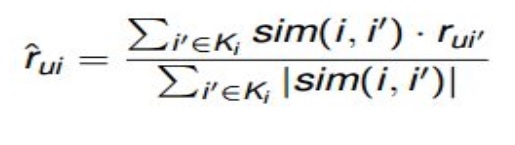
def predict(A, u,i, k=2): user_rated_i = np.where(A[:,i] !=0)[0] sim = Sim[u, user_rated_i] a = (np.argsort(sim))[-k:] nearest_s =sim[a] rating = A[user_rated_i[a],i] r_bar = (rating*nearest_s).sum()/(np.abs(nearest_s).sum()) return np.round(r_bar) predict_matrix = data_matrix.copy() for u in range(0, predict_matrix.shape[0]): for i in range(0, predict_matrix.shape[1]): if data_matrix[u,i] ==0: id = i predict_matrix[u,i] = predict(data_matrix,u,id)
Kết quả chúng ta sẽ thu được ma trận dự đoán như sau :
Từ ma trận dự đoán này bạn có thể gợi ý cho người dùng các app mặc dù họ chưa dùng nhưng bạn nghĩ họ sẽ thích nó dựa vào các điểm dự đoán. Bạn có thể tham khảo code đầy đủ tại đây
2. Item - based:
Đây là một bài toán tương tự hoàn toàn user -based chỉ khác ở chỗ các bạn sẽ dựa vào độ tương tự giữa các item thay vì độ tương tự giữa các user, nên mình sẽ không thực hiện lại. Mọi người có thể tự kiểm tra và so sánh kết quả với user - based.
3. Content - based :
Content based là phương pháp gợi ý dựa theo nội dung, ý tưởng của phương pháp này người dùng sẽ đọc những bài cùng các chủ đề mà mình yêu thích.
Trong content-based chúng ta cần xây dựng 1 bộ hồ sơ cho từng item được gọi profile item. Mỗi profile item sẽ được biểu diễn dưới dạng là 1 vector. Chúng ta sẽ sử dụng kỹ thuật TF-IDF để tạo các feature vector cho từng item.
Mình làm luôn 1 bài ví dụ để mọi người dễ hình dung nhé.
Bài toán : Xây dựng một hệ thống gợi ý để gợi ý các bộ phim dựa vào các nội dung của các bộ phim. dữ liệu của bài toán là bộ dữ liệu MovieLens 100k dataset tại kaggle.
Đầu tiên chúng ta cần import các thư viện cần thiết cho bài toán :
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from sklearn.metrics.pairwise import linear_kernel import numpy as np import pandas as pd
Bộ dữ liệu gồm 24 feature là : ‘adult’, ‘belongs_to_collection’, ‘budget’, ‘genres’, ‘homepage’, ‘id’, ‘imdb_id’, ‘original_language’, ‘original_title’, ‘overview’, ‘popularity’, ‘poster_path’, ‘production_companies’, ‘production_countries’, ‘release_date’, ‘revenue’, ‘runtime’, ‘spoken_languages’, ‘status’, ‘tagline’, ‘title’, ‘video’, ‘vote_average’, ‘vote_count’ . Ở đây mình sẽ làm một bài content-based đơn giản nên chỉ sử dụng feature overview trong tập dữ liệu.
data = pd.read_csv('movies_dataset.csv') movies_dataset = data[['id','title', 'overview']]
Sau khi load và lấy các dữ liệu cần thiết ta cần loại bỏ các “stop word” (stop word là các từ trong câu nhưng không mang ý nghĩa đặc trưng cho câu ví dụ : the, a, an, is, …). Tiếp tục chúng ta sẽ sử dụng kỹ thuật TF-IDF để tìm các đặc trưng của của các ‘overview’ trong từng bộ phim.
Nói qua về kỹ thuật TF-IDF : đây là 1 kỹ thuật xác định tần số suất hiện các từ trong đoạn văn. tf(t, d): tần suất xuất hiện của từ t trong văn bản d idf(t, D): giá trị idf của từ t trong tập văn bản
tf_idf = TfidfVectorizer(stop_words='english') overview_movies = tf_idf.fit_transform(movies_dataset['overview'])
Sau khi loại bỏ các “stop word” và tính các tần số xuất hiện của các từ thông qua TF-IDF ta tiếp tục tính sự tương quan của các câu, sử dụng công thức cosin (tương tự user-based mình đã hướng dẫn ở trên).
similarity_matrix = linear_kernel(overview_movies,overview_movies)
Sau đó chúng ta sẽ được một ma trận tương tự như này :
Cuối cùng ta cần viết một hàm dự đoán các bộ phim giống nhau dựa vào bộ phim chúng ta đã xem.
mapping = pd.Series(movies.index,index = movies['title']) def list_recommend_movies(movie_input): movie_index = mapping[movie_input] similarity_score = list(enumerate(similarity_matrix[movie_index])) similarity_score = sorted(similarity_score, key=lambda x: x[1], reverse=True) similarity_score = similarity_score[1:11] movie_indices = [i[0] for i in similarity_score] return (movies_dataset['title'].iloc[movie_indices]) list_recommend_movies('Toy Story')
Kết quả ta sẽ thu được 1 list 10 bộ phim tương tự như bộ phim “Toy Story”

Trên đây là bài viết đơn giản mình sử dụng content-based để gợi ý phim cho người coi. Vì mình chỉ dùng mỗi feature overview nên kết quả cũng có thể không thật sự chính xác nhất. bạn nên tận dụng tất cả các feature của item để xây dựng được một profile item hoàn hảo.
4. Session- based :
Sau khi tìm hiểu 2 mô hình gợi ý Lọc cộng tác và lọc theo nội dung ta thấy được để có được độ chính xác cao cho lọc cộng tác ta cần người dùng phải tương tác với hệ thống, và các sản phẩm phổ biến sẽ được nhiều đánh giá và sẽ không cân bằng cho hệ thống. Bên cạnh đó ta cũng thấy được một hạn chế của hai mô hình này là nó đều không đánh giá được mục đích của khác hàng thông qua mỗi lần khách hàng vào trang web của chúng ta. Từ những hạn chế này người ta xây dựng nên một mô hình hiện đại và cải tiến hơn đó là session- based. Chúng ta sẽ ghi lại toàn bộ các tracking của khách hàng khi vào trang web từ những lần click ảnh, click xem tiếp, dừng lại xem ảnh, like, xem review, tìm kiếm,… Sau khi phân tích ta sẽ tìm ra được mục đích của người dùng khi vào trang web là gì và sẽ gợi ý sản phẩm phù hợp cho người dùng.
Nguồn: trituenhantao.github.io