There are software bugs that can end up crippling companies if they aren't dealt with rapidly.
The Knight Capitol Group was an American financial services company. A technician forgot to copy some new code to a computer server, and this software release caused to them to lose $440 million. This happened because one of the computer servers started to rapidly purchase stock (it completed over 4 million purchases and sales) over a 45 minute period.
Not every software bug is as dramatic. But there are moments as a software developer where you have to resolve bugs as fast as you can.
I recently learned about companies releasing publicly accessible post-mortems on their emergency bugs, and dove head first into them.
What is a post-mortem?
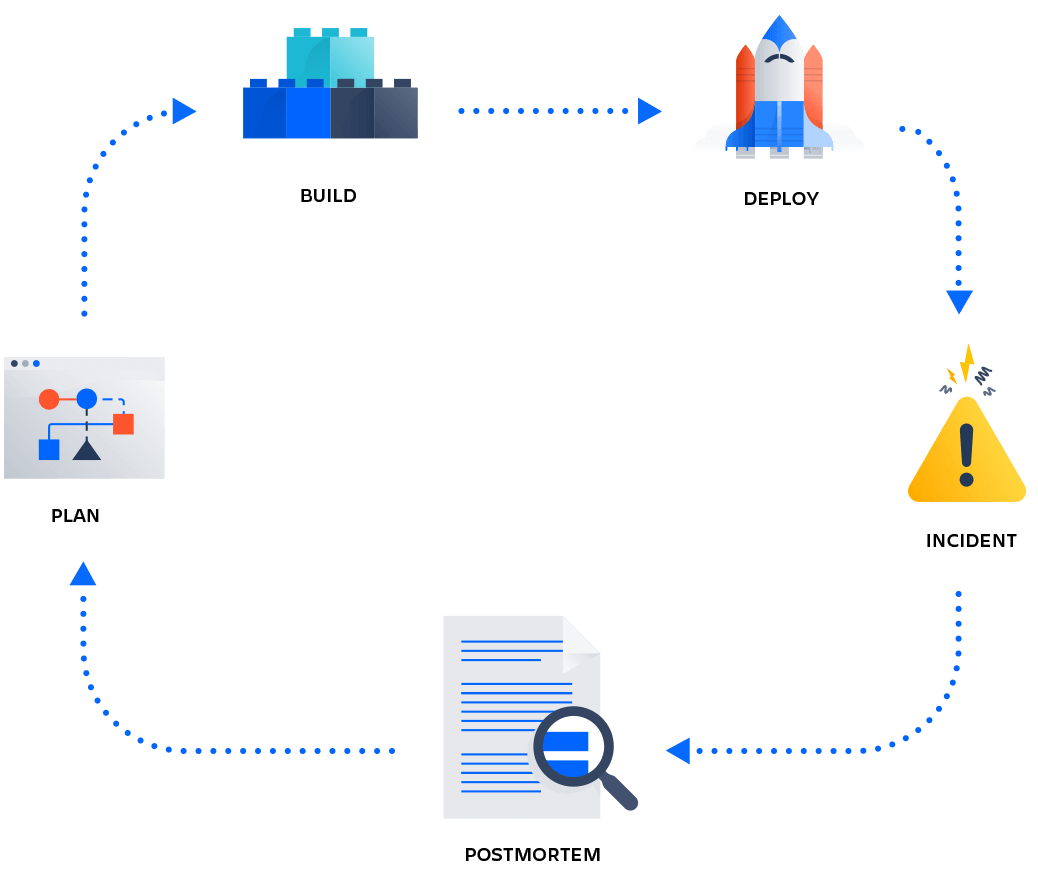
A post-mortem is where a team reflects on what went wrong with something they did, and documents it and/or amends their process to stop it happening again.
Did a software release go bad? Let's break down a timeline of where things started to go wrong, and let's reflect how we could have caught it earlier.
Here is the most important point: Post-mortems ARE NOT to assign blame. If we look at The Knight Capitol Group example, there should have been no way for one person to forget something and cripple the company.
Where was the quality assurance process where someone checked the technician's work? Did they test this before going to production? Were there no automatic tests that ran before the deploy to production succeeded?
You should be finding process failures not personal failures.
Why should we do a post-mortem?
So we can stop making the same mistake over and over!
We provide more robust, bug free, stable software by learning how we failed in the past.
Most importantly, we can catch bugs we don't even know about. And if we fix the processes that were prone to cause issues early, then those mistakes won't even happen.
We want to learn every single lesson we can from the outages and emergencies to ensure they never happen again. Nothing is more valuable than experience.

Let's look at some post-mortems together
I wanted a little bit of variety of companies and languages, so let's review some from Google, Microsoft, and Flowdock.
A common post-mortem template will contain some key details like:
- when it happened
- who owns the post-mortem (and will do the analysis)
- some lessons learned
- a rough timeline of the emergency bug and some actions from the post-mortem
So let's dive in.

If you did a Google search between 6:30 a.m. PST and 7:25 a.m. PST on January 31st, 2009, you would have seen the message "This site may harm your computer" accompanying every single result.
What happened?
Google flags search results with this message if the site is known to install malicious software. This is a warning to protect Google users, and is collated with Google's automatic algorithms, manual data entry, and a non-profit called StopBadWare.com.
One of the developers had updated the list and accidentally entered in a /, which resolved to every single site!
We know this one was human error, and because of this, Google implemented some tests and checks whenever that file changes. (And I haven't seen it happen again since 2009!)
The full post-mortem can be found here.
Microsoft
Microsoft had a 12 hour outage on February 29th, 2012.
What happened?
Microsoft have Fabric Controllers which are computers that control around 1,000 servers. It manages their life cycles, monitors their health, and restarts servers when they go down.
Isolating all these servers into 1,000 server clusters helps them keep modularity and keeps failures localized to 1 Fabric Controller (rather than all of their servers going down).
Each server in the cluster has something called a Host Agent, and this is used by the Fabric Controller to do the work it deems necessary. One of the things it handles is deploying SSL certificates to keep the servers using HTTPS, which is a way of encrypting data.
To know when these SSL certificates need to be re-generated, they take the next day at midnight and add one year. So if the Fabric Controller is creating a new certificate for a server on March 19, 1990 it will expire March 20, 1991.
Do you see where this is going? These servers attempted to generate a one year certificate for a server on a leap year. It was trying to set the certificates to expire on February 30th, 2020.
When the certificates fail to generate for the server, it terminates. And if it terminates three times in a row, it's considered to be a hardware failure, and then tells the Fabric Controller it is faulty.
The Fabric Controller, in an attempt to "heal" the failed server, will hand over the work to another server. One by one, all the servers will error out while trying to generate these certificates. And this eventually shuts down the Fabric Controller (with it's 1000 servers!).
This disaster resulted from faulty code. There are better ways to handle date problems like leap years and time-zone differences.
The full post-mortem can be found here.
Google, take two
From Thursday August 13, 2015 to Monday August 17, 2015, there were some errors on Google Cloud services, along with permanent data loss on 0.000001% of some hard drives.
What happened?
There were four successive lightning strikes on the local electrical grid that sent power to Google's computers powering Google Cloud services.
There were systems that began to immediately replace the power that was taken out by using a battery backup. Alongside manual intervention from Google employees, the service was restored with minimal permanent loss.
Google has an ongoing program of upgrading their infrastructure so that they are less susceptible to issues like this. After this, they ran analysis covering electrical distribution, software controlling the Cloud services, and the Cloud hardware being used.
The full post-mortem can be found here.
Flowdock
Flowdock instant messaging became unavailable for roughly 32 hours between April 21st and 22nd 2020. Weird behavior was also spotted, like some users not being able to log in. Also, some people found users from another organization in their organization (like Amazon employees cross-contaminated Microsoft, for example).
What happened?
Coronavirus caused a sudden spike of people working from home, which led to a higher than usual usage of Flowdock. This caused very high CPU usage and caused the database to hang whilst trying to deal with the load. There was also some permanent data loss.
The full post-mortem can be found here.
Things to keep in mind when doing a post-mortem
I read a fantastic article by Adrian Hornsby, a Principle Developer Advocate from Amazon. In it, he discussed some things to avoid, and things to emphasize in order to write the best post-mortem if you are ever the owner of one.
Here are some things he suggested:
- Don't do post-mortems to blame people, teams, or organisations. Instead, focus on the process(es) that failed to allow these mistakes to cause mischief. Never do a post-mortem to punish someone. There's no value in that, and you won't find improvements.
- Don't assume events that happened were more predictable than they were. Only because they've happened are they now obvious. (Hindsight bias)
- Make sure you go deep enough. Don't just say we saw an error in the front end code. Really dig deep into the specific error and the conditions that led to it. How can the process catch this next time? A better QA process? More peer reviews? Better error logging?
- If your resolution steps to stop it from happening are really vague like "improve documentation" or "train better", you don't understand it clearly enough to be more specific. Make these resolution steps actionable and concrete.
- Try and keep your resolution steps to things that can be done in the short term. We are trying to stop these from happening again as soon as possible. Post-mortems can spawn longer term process changes, but that's not what you're focusing on at the moment. Don't try to re-architecture something fundamental or try to change the language some huge codebase is written in.
- Let your post-mortem challenge what your team currently believes to be true. Don't assume because everyone believes something to be true that it is (Common belief fallacy)
How to learn more
If you enjoyed this, you can find more public post-mortems here. These include post-mortems from the companies we have already discussed along with examples from Amazon, GitHub, Linux, Heroku, Spotify, Valve, Cloudfare, Etsy, GoCardless, Travis CI and more.
Conclusion
I hope this has explained what a post-mortem is in the software development lifecycle, how to effectively write one, and common mistakes that happen when you write your first few.
www.freecodecamp.org