Directive No-index hướng dẫn các công cụ tìm kiếm loại trừ một trang khỏi chỉ mục, khiến nó không đủ điều kiện xuất hiện trong kết quả tìm kiếm.

Thẻ Meta Robots No-index
Cách phổ biến nhất để hướng dẫn các công cụ tìm kiếm không lập chỉ mục một trang là bao gồm thẻ Meta Robots trong tag <head> của trang HTML với directive “noindex” như bên dưới:
<meta name=”robots” content=”noindex” />
Khoảng năm 2007, các công cụ tìm kiếm lớn đã bắt đầu triển khai hỗ trợ cho directive "noindex" trong các thẻ Meta Robots. Các thẻ Meta Robots cũng có thể bao gồm những directive khác, chẳng hạn như "follow" hoặc "nofollow", hướng dẫn các công cụ tìm kiếm hoặc không thu thập dữ liệu (crawl) về các liên kết được tìm thấy trên trang hiện tại.

Thẻ No-index ngăn công cụ tìm kiếm lập chỉ mục trang
Thông thường, các quản trị viên web sẽ sử dụng directive "noindex" để ngăn nội dung không được lập chỉ mục đối với những công cụ tìm kiếm.
Một số trường hợp sử dụng phổ biến cho directive "noindex" là:
- Các trang chứa thông tin nhạy cảm
- Giỏ hàng hoặc trang thanh toán trên trang web thương mại điện tử
- Phiên bản thay thế của các trang để thực hiện A/B test hoặc split test (so sánh 2 phiên bản trong cùng 1 môi trường để đánh giá hiệu quả)
- Các phiên bản đang thực hiện, chưa sẵn sàng để sử dụng công khai
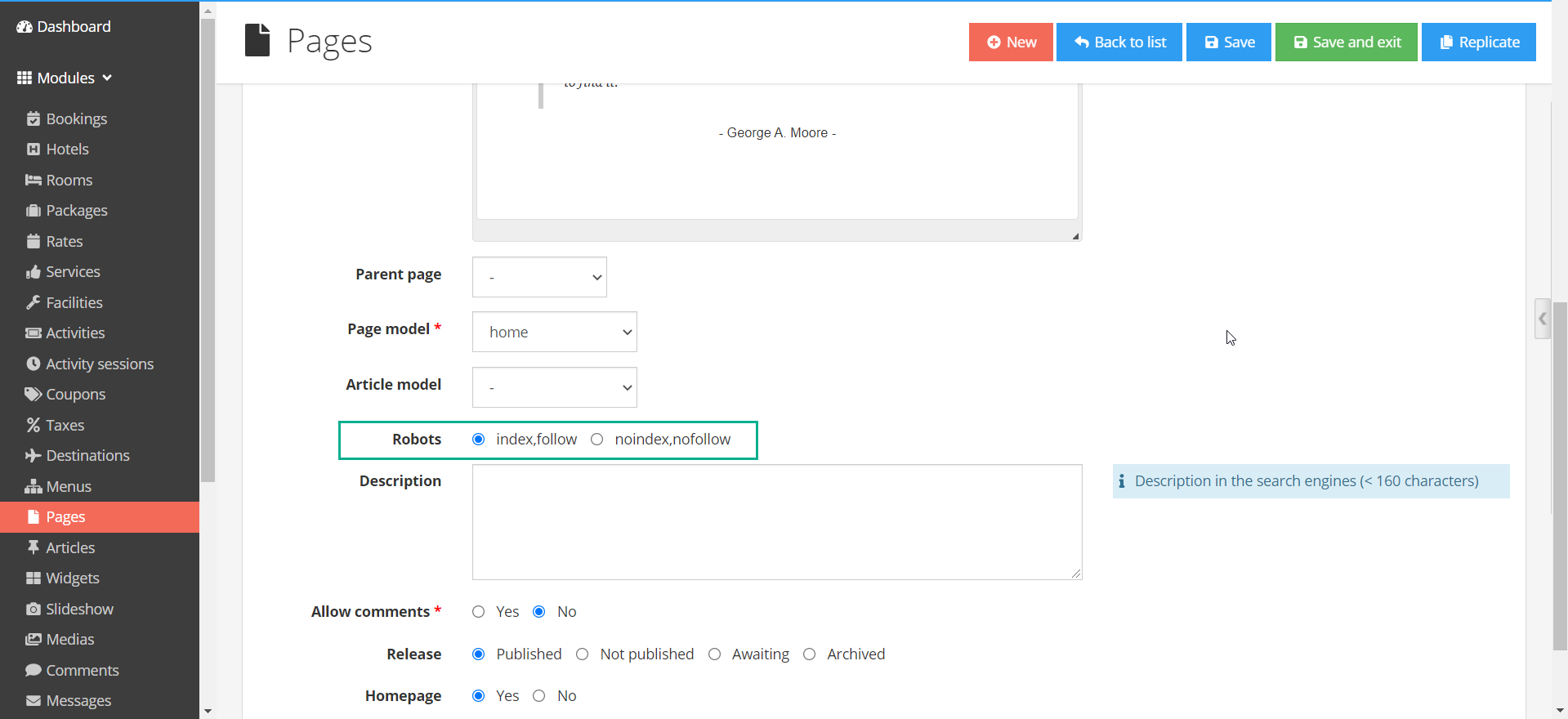
Response header "noindex"
Ngoài ra, các công cụ tìm kiếm hỗ trợ một directive "noindex" được phân phối thông qua những response header HTTP cho một trang nhất định. Mặc dù cách tiếp cận này ít phổ biến và có thể khó xác định hơn so với việc sử dụng các công cụ SEO phổ biến, nhưng đôi khi lại dễ dàng hơn để các kỹ sư hoặc quản trị viên web bao gồm dựa trên cấu hình server.
Tên và giá trị của response header "noindex" như sau:
X-Robots-Tag: noindex
Cách sử dụng directive "noindex" trong SEO
1. Tránh sử dụng "noindex" trên các trang có giá trị
Việc vô tình đưa vào thẻ hoặc directive "noindex" trên một trang có giá trị có thể khiến trang đó bị xóa khỏi mục lục của công cụ tìm kiếm và ngừng nhận tất cả traffic organic.
Ví dụ, nếu một phiên bản trang web mới được tung ra, nhưng các thẻ "noindex" được bao gồm để ngăn các công cụ tìm kiếm lập chỉ mục những phiên bản trang mới trước khi chúng sẵn sàng, thì phiên bản trang web mới có thể ngừng nhận lưu lượng truy cập từ việc tìm kiếm ngay lập tức.
2. Phải hiểu rằng "noindex" trực tiếp được coi là "nofollow"

"Noindex" trực tiếp được coi là "nofollow"
Các quản trị viên web thường sử dụng thẻ Meta Robots hoặc response header để báo hiệu cho các công cụ tìm kiếm rằng, trang hiện tại không nên được lập chỉ mục, nhưng các liên kết trên trang vẫn phải được thu thập thông tin, như với thẻ Meta Robots sau:
<meta name=”robots” content=”noindex,follow” />
Điều này thường được sử dụng cho các trang danh sách phân trang. Ví dụ, “noindex,follow” có thể được áp dụng cho một danh sách lưu trữ cho blog, để ngăn các trang lưu trữ xuất hiện trong kết quả tìm kiếm, nhưng cho phép các công cụ tìm kiếm thực hiện thu thập dữ liệu, lập chỉ mục và xếp hạng các bài đăng trên blog.
Tuy nhiên, cách tiếp cận này có thể không hoạt động như dự định, vì Google đã giải thích rằng các hệ thống của hãng này cuối cùng sẽ coi directive “noindex,follow” là “noindex,nofollow”. Nói cách khác, Google sẽ ngừng thu thập các liên kết trên bất kỳ trang nào có directive "noindex". Điều này có thể ngăn các trang đích liên kết không được lập chỉ mục, giảm PageRank hoặc quyền hạn, hạ thứ hạng của trang đó cho các từ khóa có liên quan.
3. Tránh sử dụng các quy tắc "noindex" trong file Robots.txt
Mặc dù không bao giờ được hỗ trợ chính thức, nhưng trước đây, công cụ tìm kiếm luôn tôn trọng các directive "noindex". Vì quy tắc robot.txt với ký tự đại diện có thể áp dụng cho nhiều trang cùng một lúc, mà không có bất kỳ thay đổi nào được yêu cầu trong chính các trang đó, nên phương pháp này được nhiều quản trị viên web ưa thích. Google không khuyến nghị sử dụng các file robot.txt này để thiết lập các directive "noindex" và đã dừng code hỗ trợ các quy tắc này vào tháng 9 năm 2019.