Lời mở đầu
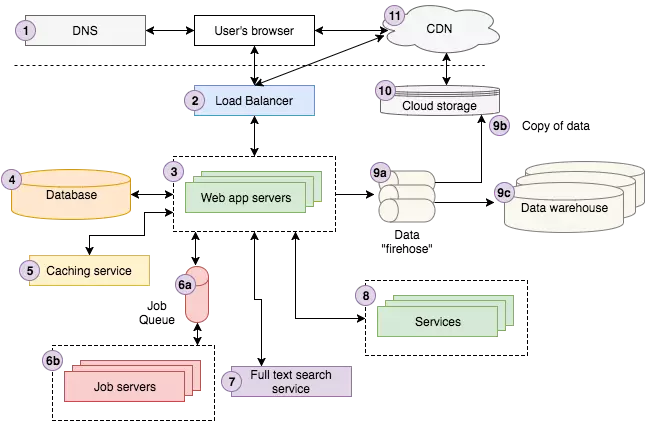
Sơ đồ trên đây là một ví dụ về cấu trúc hệ thống, các thành phần tạo nên một trang web. Bạn sẽ thấy sơ đồ trên khá phức tạp nếu chưa có nhiều kinh nghiệm trong lĩnh vực web development. Vì thế những hướng dẫn dưới đây sẽ giúp bạn hiểu rõ hơn về từng thành phần trong đó.
Giả sử có người dùng tìm kiếm từ khóa "Strong Beautiful Fog and Sunbeams in the Forest", kết quả tim kiếm đầu tiên là hình ảnh đến từ trang Storyblocks. Khi bấm vào kết quả tìm kiếm, trình duyệt web chuyển hướng đến trang web cụ thể có hình ảnh đó. Bản chất sự điều hướng là trình duyệt request tới server DNS để tìm cách truy cập vào trang Storyblocks, sau đó sẽ gửi request đến đó.
Request sẽ đi tới load balancer, là công cụ để tiếp tục chuyển request tới một trong số những web server đang hoạt động. Request khi đến webserver thì webserver sẽ tìm kiếm xem trong cache server có chứa thông tin hình ảnh không để kéo dữ liệu từ cache server về, nếu không thì sẽ lấy từ database.
Tiếp theo, người dùng tìm kiếm những bức ảnh tương tự bằng cách nhập tiêu đề bức ảnh vào ô tìm kiếm. Trình duyệt sẽ gửi request tới dịch vụ full-text search, với đầu vào là những gì người dùng đã nhập để cho dịch vụ full-text search tìm kiếm.
Do người sử dụng web là thành viên đã đăng ký của Storyblocks, hệ thống sẽ tìm kiếm thông tin của người dùng qua dịch vụ lưu trữ thông tin tài khoản.
Cuối cùng, toàn bộ dữ liệu hiển thị trang web được truyền vào một đường dẫn file để đưa lên trên hệ thống lưu trữ trực tuyến, sau đó đưa vào kho dữ liệu, cuối cùng gửi về trình duyệt của người dùng. Trình duyệt sẽ hiển thị những file đã kéo về để người dùng sử dụng.
Đó là ví dụ tóm tắt luồng hoạt động khi bạn truy cập vào trang web Storyblocks. Những phần dưới đây sẽ giới thiệu qua về từng thành phần để bạn có thể hiểu được chúng là gì và hoạt động như thế nào.
1. DNS
DNS là từ viết tắt của "Domain Name System" và đây là công nghệ làm nền móng cho các hoạt động diễn ra trên world wide web. Ở mức cơ bản nhất, DNS cung cấp cặp giá trị tìm kiếm key/value từ một tên domain (ví dụ như google.com) tương ứng với một địa chỉ IP (ví dụ như 85.129.83.120). Để bạn có thể truy cập vào một trang web nào đó thì máy tính cần thông tin các cặp key/value này để điều hướng request tới một server cụ thể. Nó cũng giống như danh bạ điện thoại của bạn, khi bạn cần gọi điện thoại cho người thân có tên "Trâm Anh" số điện thoại lưu trong danh bạ là "0969666996". Giống như việc bạn cần phải có danh bạ để tìm số điện thoại của người có tên Trâm Anh, bạn cũng cần DNS để tìm kiếm địa chỉ IP của địa chỉ domain nào đó. Vì vậy có thể coi DNS như một danh bạ điện thoại cho internet.
Chúng ta có thể tìm hiểu cụ thể hơn về vấn đề này, nhưng ở mức 101 thì không cần thiết phải tìm hiểu sâu đến vậy.
2. Load balancer
Trước khi tìm hiểu load balancing, cần phải làm rõ khái niệm "ứng dụng mở rộng theo chiều ngang" (horizontal scaling) và "ứng dụng mở rộng theo chiều dọc" (vertical scaling). Chúng là gì và khác nhau như thế nào? Vertical Scaling là gia tăng câu hình cho máy chủ sẵn có của bạn (nâng cấp RAM, CPU), còn Horizontal Scaling là gia tăng số lượng máy chủ trong hệ thống
Trong hầu hết các trường hợp, bạn chỉ nên scale ứng dụng theo chiều ngang. Vì nếu chỉ có một máy chủ hoạt động, nhiều khi gặp phải sự cố sẽ không hề có biện pháp back-up nào khác. Mà đương nhiên không phải lúc nào máy chủ cũng hoạt động trơn tru. Chưa kể đến đôi lúc mạng chập chờn, toàn bộ hệ thống dữ liệu sẽ dừng hoạt động nếu chỉ có một server. Hệ thống nhiều server cho phép bạn có một phần "sai sót" trong lúc vận hành, đảm bảo ứng dụng vẫn hoạt d odongj ngon lành (fault tolerant).
Ngoài ra, sử dụng phương pháp horizontal scaling giúp bạn tách biệt chức năng các thành phần khác nhau trong hệ thống backend (bao gồm web server, database, service bên thứ 3, ....). Đơn giản chỉ cần cho mỗi loại chạy một con server khác nhau.
Và cuối cùng, nhược điểm lớn nhất của vertical scaling là....không thể scale được nữa. Không hề tồn tại một siêu máy tính nào có thể giải quyết mọi vấn đề của bạn trong một . Giả sử như nền tảng tìm kiếm của Google, thử tưởng tượng toàn bộ kết quả, thông tin gợi ý chỉ được lưu trên một con server, thì server phải khủng như nào mới chịu nổi...? Mà cũng không cần kể đến google, ngay cả những service tại các công ty nhỏ hơn nhiều, hoặc chính những dự án thường ngày của bạn cũng cần thiết phải chạy nhiều server AWS EC2 (một service máy chủ cung cấp bởi amazon) - từ 150 đến 400 con hàng ngày thì mới đáp ứng được lượt truy cập từ người dùng.
Trờ lại với Load Balancer, đây là công cụ hỗ trợ cho "horizontal scaling". Load balancer điều hướng những request từ phía người dùng đến các con server khác nhau trong hệ thống của bạn. Tất cả các server này đều giống hệt nhau về cấu hình. Và sau khi application server xử lý xong request thì sẽ trả về response về cho phía client. Việc xử lý request, trả về response ở tất cả các server này đều giống nhau, nên nhiệm vụ của Load Balancer là phân đều các request cho các server đang chạy để đảm bảo không có lúc nào bị "quá tải"
3. Web application Servers
Về cơ bản, định nghĩa web application server khá là dễ hiểu. Những server này có nhiệm vụ thực hiện business logic, xử lý request từ phía người dùng và trả về HTML cho trình duyệt. Để làm được việc này, web application server phải giao tiếp, tương tác với nhiều thành phần backend khác như databases, caching services, job queues, search services, và một số microservices khác. Như đã đề cập trong phần load balancer, thường thì bạn sẽ có nhiều hơn hai (hoặc rất nhiều!!) web application server cùng trỏ vào một load balancer để nhận request từ người dùng.
Để thiết lập một web application server thì bạn cần phải chọn một ngôn ngữ lập trình cụ thể (Node.js, Ruby, PHP, Scala, Java, C#, .NET,...) và một framework MVC cho ngôn ngữ đó (Express đối với Node.js, Ruby on Rails, Play - Scala, Laravel - PHP,...) Trong bài viết này sẽ không đi sâu vào các framerwork này.
4. Database server
Hầu hết các trang web hiện tại đều sử dụng ít nhất một hệ thống quản trị cơ sở dữ liệu (database) để lưu trữ dữ liệu, thông tin sử dụng của ứng dụng web đó. Database cho phép bạn thiết kế cấu trúc dữ liệu, truy xuất và sửa đổi dữ liệu, thêm dữ liệu mới, thực hiện tính toán trên các dữ liệu sẵn có. Phần lớn các app server sẽ tương tác trực tiếp với chỉ một database. Hoặc mỗi backend service có một database riêng tách biệt so với phần còn lại của hệ thống
SQL là viết tắt của "Structured Query Language", được ra đời vào những năm 1970 để cung cấp cho bộ phận lớn đối tượng sử dụng một phương pháp phổ biến nhằm truy cập những dữ liệu có liên quan đến nhau. SQL database lưu trữ dữ liệu vào các bảng, kết nối với nhau qua một trường chung gọi là ID (thường là số nguyên dương). Cụ thể hơn, đây là một ví dụ về một hệ thống database, lưu trữ thông tin dịa chỉ nhà của người dùng. Để lưu trữ thông tin này bạn cần có hai bảng, một bảng "users" và một bảng "addresses", liên kết với nhau qua ID của "users", cụ thể qua hình vẽ dưới đây:
Còn NoSQL, như tên gọi của nó là không sử dụng cách thức SQL như trên. Đây là công nghệ lưu trữ giữ liệu mới ra đời nhằm phục vụ mục đích xử lý một lượng lớn dữ liệu đến từ những trang web luôn luôn mở rộng. Vì phần lớn hệ quản trị CSDL đều gặp vấn đề trong việc horizontal scaling, và chỉ có thể vertical scale đến một mức nào đó. Nếu như bạn chưa biết gì về SQL, đây là một số tài liệu cơ bản giúp bạn tìm hiểu sơ qua về khái niệm này:
- https://www.w3resource.com/mongodb/nosql.php
- http://www.kdnuggets.com/2016/07/seven-steps-understanding-nosql-databases.html
- https://resources.mongodb.com/getting-started-with-mongodb/back-to-basics-1-introduction-to-
5. Caching service
Service cache sử dụng phương thức lưu trữ dữ liệu dạng key/value để bạn có thể truy xuất dữ liệu bất cứ lúc nào. Việc lưu trữ cập nhật dữ liệu mới và truy xuất dữ liệu sẵn có trong hệ thống cache chỉ mất thời gian theo độ phức tạp O(1). Phần lớn các trang web tận dụng công cụ caching để lưu kết quả của những thao tác phức tạp để có thể lấy ra kết quả này chỉ sau lần đầu tiên thực hiện. Như vậy phần backend không phải thực hiện tính toán, thao tác lại đối với những request giông nhau, để giúp giảm tải cho những hệ thống backend khác. Chỉ cần tìm đúng key tương ứng với request tương tự là có thể lấy ra được kết quả lưu trong value tương ứng. Chảng hạn như hệ thống cache sẽ lưu trữ kết quả của những câu query database phức tạp, tốn thời gian, hoặc data trả về từ việc gọi tới API bênthứ ba,.... Sau đây là một số ví dụ thực tế về việc sử dụng caching:
- Google lưu cache cho những kết quả tìm kiếm phổ biến như "Notre Dame", "Trâm Anh", "clip 9 phút",.... thay vì thực hiện tính toán cho mỗi lần người dùng gõ tìm kiếm.
- Facebook caches khá nhiều dữ liệu cho mỗi lần bạn login, chẳng hạn như các bài Post, danh sách bạn bè,...
- Trang web Storyblocks cache HTML trả về từ React phía server-side, kết quả tìm kiếm,...
Hai công nghệ sử dụng cho việc caching phổ biến nhất hiện nay là Redis và Memcache.
6. Job Queue và Servers
Khi bạn nhìn vào một trang web, ngoài những thứ mà trình duyệt hiển thị cho bạn thấy thì bên dưới server của trang web đó cần phải xử lý rất nhiều thao tác phụ không liên quan đến việc xử lý request của người dùng. Chẳng hạn như Google cần phải crawl dữ liệu, đánh địa chỉ cho toàn bộ hệ thống internet để trả về một kết quả tìm kiếm. Điều này không được thực hiện vào mỗi lần bạn tìm kiếm, mà hệ thống server của google sẽ crawl dữ liệu trên web một cách bất đồng bộ, và cập nhật chỉ mục trong lúc crawl đó.
Mặc dù có thể có nhiều công nghệ khác nhau phục vụ cho những tác vụ bất đồng bộ, phổ biến nhất vẫn là công nghệ có tên gọi "job queue", bao gồm 2 thành phần: Một queue bao gồm các "jobs" cần phải chạy, và một Server (thường được gọi là "workers") dùng để chạy những job đó
Job queues lưu trữ những job cần phải chạy bất đồng bộ. Nguyên tắc đơn giản nhất là FIFO - vào trước thì được chạy trước. Tuy nhiên nhiều hệ thống phải chạy job dựa trên độ ưu tiên trong queue. Mỗi khi ứng dụng cần phải chạy job, workers sẽ thêm job đó vào trong queue và chỉ chờ đến lượt chạy.
7. Full-text Search service
Nhiều trang web hỗ trợ một số tính năng search giúp người dùng có thể tìm kiếm những thông tin thích hợp nhất với thông tin người dùng nhập vào. Công nghệ hỗ trợ cho tính năng này thường được biết đến với cái tên "full-text search", qua việc tận dụng "index ngược" để nhanh chóng tìm kiếm dữ liệu kết quả tương ứng với từ khóa tìm kiếm

Mặc dù một số database có thể hỗ trợ full-text search trực tiếp (chẳng hạn như SQL), nhưng bạn vẫn nên tách riêng service full-text search ra và sử dụng như một ứng dụng riêng.
8. Services
Khi ứng dụng scale đến một mức độ nào đó, sẽ cần phải sử dụng một số "services" tách ra từ hệ thống gốc để chạy như một ứng dụng độc lập. Những thành phần này người dùng không thể nhìn thấy, nhưng những hệ thống khác trong hạ tầng luôn tương tác với chúng. Chẳng hạn như trang web Storyblocks có một số services như sau:
- Account Service lưu trữ dữ liệu của người dùng ở tất cả các trang khác nhau để có được trải nghiệm đồng bộ hóa tốt hơn và có cơ hội đặt offer ở tất cả các trang này.
- Content service lưu trữ thông tin metadata của tất cả các file video, âm thanh, hình ảnh, cung cấp một môi trường để tải xuống những file này, đồng thời rà soát cả lịch sử tải xuống của chúng.
- Payment service cung cấp môi trường thanh toán bằng thẻ tín dụng.
- HTML -> PDF service là nền tảng chuyển đổi một trang web muốn hiển thị ở dạng file pdf
9. Data
Ngày nay, yếu tố dữ liêu đóng vai trò khá quan trọng trong việc quyết định sự sống còn của một công ty. Phần lớn các ứng dụng hiện nay tận dụng tối đa lợi ích của một quy trình xử lý dữ liệu dữ liệu để đảm bảo việc thu thập, sắp xếp và phân tích một cách đầy đủ. Một quy trình xử lý dữ liệu gồm các bước sau đây:
- Ứng dụng gửi dữ liệu (sự kiện từ tương tác của người dùng) tới đường dẫn data, nơi tuh thập và xử lý dữ liệu. Thường thì những dữ liệu sẽ được chuyển hóa, phân chia tới những đường dẫn khác. AWS Kinesis và Kafka là hai công nghệ thông dụng nhất cho việc này.
- Dữ liêu sẽ được lưu trữ trên một dịch vụ lưu trữ cloud nào đó. AWS Kinesis hỗ trợ sử dụng chuyển hướng dữ liệu tới một nơi lưu trữ của cùng hệ thống là Amazon S3
- Dữ liệu cuối cùng thường sẽ được đưa vào một kho tổng hợp để phân tích. Rất nhiều công ty sử dụng AWS Redshift để phục vụ mục đích này. Ngoài ra còn có Oracle để xử lý những dữ liệu phức tạp hơn.
10. Cloud storage
Cloud storage là một công cụ dùng để lưu trữ, truy cập và chia sẻ dữ liệu trên toàn hệ thống Internet. Bạn có thể sử dụng cloud storage để giữ bất cứ file nào bạn cần, tương tự như việc để chúng trên máy local của bạn. Điểm ưu việt là cloud storage có thể tùy ý scale, đồng thời bạn có thể tương tác với dữ liệu thông qua RESTful API thay vì phương thức HTTP. Amazon S3 là công cụ cloud storage phổ biến nhất hiện nay mà hầu hết các trang web đều sử dụng nhằm lưu trữ dữ liệu cần thiết như ảnh, video, file CSS, Javasript,....
11. CDN
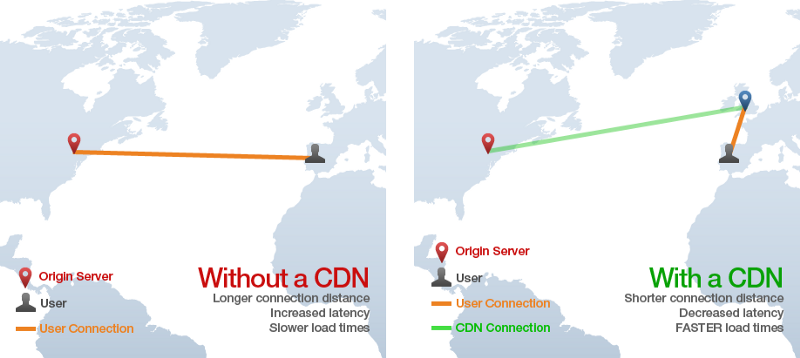
CDN là viết tắt của "Cloud Delivery Network". Công nghệ này cho phép người dùng tải về những file tĩnh (HTML, CSS, JS, ảnh,...) từ một server gần mình nhất, thay vì phải tải về từ server gốc. Điều này cho phép tốc độ load dữ liệu, tải file nhanh hơn rất nhiều. Nguyên lý hoạt động của CDN là copy những content từ một server gốc, phân bố tại các "edge" server trên khắp thế giới. Khi một người dùng request đến một file nào đó tới server, dịch vụ CDN sẽ tìm tời "edge" server gần với địa điểm của người dùng nhất, và trả về file lưu trong những server đó. Như vậy tốc đồ tải file của trình duyệt sẽ tăng lên rất nhiều, vì server trả về file ở gần người dùng hơn so với server gốc. Ví dụ như khi một người dùng tại Tây Ban Nha vào một trang web có trụ sở server tại New York, các file dữ liệu tĩnh sẽ được lấy ra từ một CDN "edge" server được đặt tại Anh.
Nguồn: https://engineering.videoblocks.com/web-architecture-101-a3224e126947
Dịch bởi Tạ Duy Vinh (viblo).