
For years I have developed web apps with the idea of soft deletes: when data is deleted, it is simply marked as “deleted”, but not actually deleted from the database.
One of the main reasons for this is that, well, users tend to like clicking buttons – including “delete” – without actually reading those final confirmation prompts. While backups can capture older data, if data has been created and deleted since the last backup was run, there’s no way to recover it.
Soft deletes resolves this: the data still exists in the database, and it is possible to clear the deleted flag.
For years I’ve implemented soft deletes in systems, initially using a Boolean flag (is it deleted, yes or no) but more recently using a timestamp of when it was “deleted”. And of course by “delete”, I actually mean an update to mark it as deleted.
But it isn’t perfect… and had me reading around to see if there are other ways to handle “deleting” data from the database, and basically it comes down to three general approaches:
- Soft deletes: marking data as deleted
- Hard deletes: performing a DELETE on a table
- An audit approach: moving a representation of the data to an audit log, then performing a hard delete
Hard deletes are scary and incredibly final. And as mentioned, users will delete things and want them back, so that’s not ideal. Being able to restore deleted data, while rare, is incredibly useful.
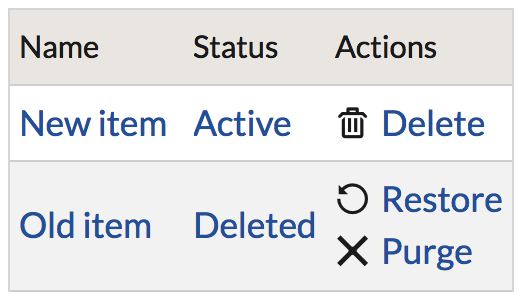
Why I love soft deletes
Recoverability is the first reason. Users can’t actually delete delete data, so it is reassuring to know that data can be restored if something is accidentally deleted, and not have to rely on a backup (note, backups are still important, and always in use with my hosting, but can’t always catch quick changes).
This also lends itself to easily recovering data in the event of needing to review data – maybe it is a HR issue where someone left an offensive comment, or even a legal request to refer back to an action that someone performed. Soft deletes make this easily possible – while still giving users the impression that it has been deleted. That sounds really misleading, and is not intended that way, but is more of a business consideration than anything: remember, the internet is written in ink, and even if you’re behaving like a pratt, your actions (and your data) may need to reviewed, especially in a business application environment.
The biggest benefit here is that the data is still in their queryable database tables – and queries can be written at the database level to get exactly the data that is needed for that given user.
What’s the catch?
Using soft deletes does create a few considerations though.
Performance
The first is the potential for performance issues. Using MySQL (or MariaDB) doesn’t (at this time) provide partial indexing, so we rely on complete indexing of tables: and this means all “deleted” data is included in the index given it still does exist.
Adjusting indexing and thoroughly working through each query to optimise and streamline its performance is key – and while significant performance hits may not be noticed for years (as data grows) for some applications, it is a consideration.
Structure
The other catch is structural. A really simple example is a “users” table – let’s imagine that we have a field for the email address that has been defined as UNIQUE in the schema.
If a user is created, then soft deleted, they are still in the database. If another INSERT is performed that tries to create a new user with the same email address, the query will fail due to the UNIQUE constraint.
To overcome this, the UNIQUE constraint needs to be removed from the column – but in doing so, we are no longer saying, at the database level, that the email address must be unique: this business rule is now solely in our code – and the question of whether this is the place for this rule to be.
The DBMS should be helping enforce the structure and integrity of our data – and using soft deletes means we need to purposely work around constraints such as UNIQUE – and in doing so, potentially compromise the full usefulness of the schema within the DBMS.
Accuracy
The third is query accuracy. And this varies based on how you’re approaching your queries.
If you are writing your own queries, it is your responsibility as a developer to ensure that you are excluding “deleted” data from each query. Every time. Every single query. Every where.
And all it takes is one query to miss that “deleted” check to return inaccurate data. We are human, after all, and humans make mistakes.
However, helpfully in a framework like Laravel, Eloquent has been designed to handle soft deletes, and includes a trait that can be applied to a model that automatically configures it for soft deletes.
Any time “delete” is called on a model that has the SoftDeletes trait, Laravel will update the “deleted at” timestamp for us – and any Eloquent queries that are run on that model collection will automatically exclude “deleted” records.
While that is really helpful within Laravel, if you’re developing in a different framework, remembering to exclude deleted data is now our responsibility.
Why an audit table sounds enticing
While Googling around, I found a 6 year old article by James Halsall about “why soft deletes are evil and what to do instead”, and poses the idea of an audit log through event dispatching.
The basic idea is that when your data is being deleted, you store a serialized representation of the original data, as well as who deleted it, when, and what model it belonged to.
When this event has been fired, a hard delete can then be performed on the actual record.
This means we tick off the concerns above about soft deletes:
- Performance can be better as the database tables contain less data (i.e. the deleted data is not in the core tables)
- The database structure can correctly use constraints like UNIQUE
- Queries, if written correctly of course, will be accurate because deleted data doesn’t need to be filtered out (after all, it doesn’t exist in the core tables anymore)
With the requirement to recover deleted data being a rare job, this sounds like a really smart approach.
Audit table considerations
I posed the question on Twitter, and one response raised concerns about how to meet GDPR requirements with an audit approach.
While I’m not an expert at GDPR requirements and obligations, I understand the basics. And for an audit log, being able to easily identify which log entries belong to a specific user is crucial.
This poses the question of how do we know what user (or even users) the deleted data belongs to?
If we use consistent naming for “user_id” for example, then if our deleted data includes that column name, we can use that value.
But what about when there are multiple user ID fields in a model – maybe it is a message which has a “from_user_id” and “to_user_id” pair of fields? These need to be correctly mapped to the audit log too.
One approach that I may have a tinker with is to write a Trait for my Laravel app that overrides “delete” for a model, and fires the event to add it to the audit log – but also extend it further by having a configurable parameter within the Trait, and overridable per model, that can tell the audit log what fields in the model should be used when relating to the audit log entry. And you know what… this post is long enough already, so will write another post about this dev work.
I’ve seen there are packages that can help with auditing – but do more than just handle storing deleted models – but could still be reviewed. Once again, comes down to the business needs as to whether an existing package fits the bill, is doing too much, not enough, or not meeting the data requirements.
Should data ever be deleted?
In a business application, this is an interesting idea to consider too.
After an order has been taken, should it be deleted? Or should its status updated to be “cancelled”?
When an employee leaves an organization, should their account be deleted (along with any comments, references or other related models), or deactivated but still able to appear in historical data?
Both of these examples give weight to not actually deleting data, but rather changing status. It means your application has a complete and accurate view of all of its data over time, not just what is happening right now.
While keeping data and changing its status can make a certain degree of sense, it also is no better than the soft delete approach. Performance is a consideration, structural constraints like UNIQUE are not handled (i.e. a username field can never be reused) and you need to remember to filter out data that shouldn’t be reported on.
On the other hand, think about a blog post in your CMS: maybe you want to just delete it for good. Sure, it could be unpublished, but why not just delete it? There’s no value in keeping it if you decide to delete it. A solid use case for a hard delete.
This is idea beyond what to do at the database level (and how your deleting operation works), but one to review at the business level. There are cases where data should never ever be deleted (but have its status changed), but also there are cases where data could be deleted without impacting historical data.
So it’s a bit soft and a bit hard. And a valid argument that maybe an application needs both.
Combining ideas
Just an idea… but it could be possible to combine all three: soft, hard and audit.
Your system could handle soft deletes initially – and think of this like deleting a file on your computer and having it appear in the Trash. It can be recovered, or deleted – but it’s out of your way for the moment.
Then you could empty the Trash, or even have a script that runs periodically to clear out old (i.e. deleted more than 30 days ago) with placing in the audit log, and performing the hard delete.
Additional and unwarranted complexity, or a balance between recoverability and performance?
Again, it depends on your app, but has at least got me thinking of how to approach different data sets, different use cases, and different business needs: and knowing that while soft deletes aren’t necessarily wrong, they may not always be right either.
There is no perfect and simple answer that works in every single case – and goes beyond just the technology but also to the business rules needed.
Hard deletes still are very final, and soft deletes can create some concerns to consider, is the implementation of an audit log solving the problem and finding the best of both hard and soft deletes?
What sort of developer are you? A soft deletion? A hard deletion? Drop me a line and let me know why you like your approach to deleting data.
Via martyfriedel


![Eric Evans is a pioneer within the field of domain-driven design. According to him “[e]very model represents some aspect of reality or an idea of interest. A model is a simplification. It is an interpretation of reality that abstracts the aspects relevant to solving a problem at hand and ignores extraneous detail in domain-driven design.”](/sites/default/files/styles/style_383_222/public/2020-08/Domain-Driven-Design_cover-1200x675_0.jpg?itok=HQ83yZLL)