Code và data đều là những thành phần cốt lõi của một hệ thống AI. Vậy các nhà phát triển nên tập trung vào yếu tố nào hơn? Để giúp bạn có được câu trả lời, bài viết dưới đây sẽ so sánh hai cách tiếp cận Data-centric và Model-centric trong học máy. Hãy đọc đến cuối để tìm thấy một số tips thú vị về cách áp dụng cơ sở hạ tầng tập trung vào dữ liệu (data-centric infrastructure) nhé!
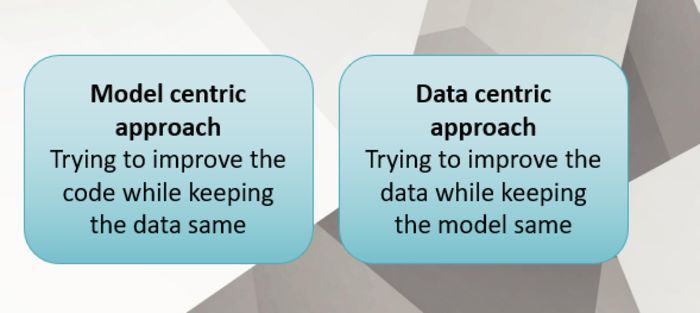
Phương pháp model-centric
Phương pháp model-centric lấy việc xây dựng mô hình làm trung tâm, tức là phát triển các nghiên cứu thử nghiệm để cải thiện độ chính xác và hiệu suất của mô hình học máy. Điều này liên quan đến việc lựa chọn một kiến trúc mô hình tốt nhất và xây dựng quy trình huấn luyện từ nhiều kịch bản.
Trong cách tiếp cận model-centric, dữ liệu được giữ nguyên và các lập trình viên tiến hành cải tiến thuật toán hoặc kiến trúc mô hình hoặc tối ưu code. Do đó việc xây dựng các thuật toán, mô hình tính toán mạnh thậm chí phức tạp và tối ưu code là mục tiêu trọng tâm của cách tiếp cận này.
Xu hướng model-centric trong AI
Hiện tại, phần lớn các ứng dụng AI đều tập trung vào mô hình, đặc biệt là trong các nghiên cứu học thuật. Theo Andrew Ng, một chuyên gia tại thung lũng Silicon, hơn 90% các bài báo nghiên cứu trong lĩnh vực AI đang tập trung vào mô hình. Một trong số các nguyên nhân chính là do rất khó để xây dựng những bộ dữ liệu quy mô lớn được cả cộng đồng khoa học cùng công nhận. Tuy nhiên, chính vì tập trung vào phát triển mô hình nên dữ liệu thường bị bỏ qua, và việc thu thập dữ liệu được xem như việc chỉ diễn ra một lần trong suốt quá trình xây dựng các hệ thống AI.
Phương pháp data-centric
Khi dữ liệu trở thành yếu tố cốt lõi của mọi quyết định, thì một doanh nghiệp áp dụng tốt phương pháp data-centric có thể hoạch định hoặc điều chỉnh chiến lược một cách phù hợp, từ đó cải thiện hiệu suất vận hành nhờ những phân tích chính xác, có tổ chức và minh bạch dựa trên dữ liệu.
Cách tiếp cận data-centric liên quan đến việc thay đổi/cải tiến bộ dữ liệu một cách có hệ thống để tăng độ chính xác của mô hình học máy. Xây dựng các bộ dữ liệu đủ đa dạng và chất lượng là mục tiêu trọng tâm của phương pháp này.
Phân biệt data-centric với data-driven
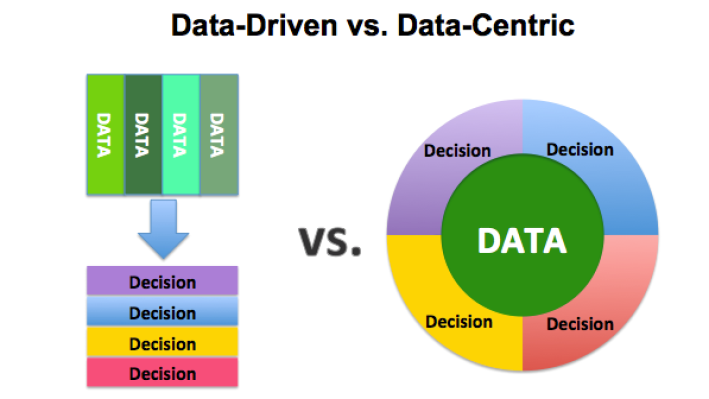
Nhiều người thường nhầm lẫn giữa data-centric và data-driven. Data-driven là một phương pháp để thu thập, phân tích và trích xuất thông tin hoặc tri thức ẩn chứa bên trong dữ liệu. Mặt khác, phương pháp data-centric tập trung vào việc sử dụng dữ liệu để xác định các bước đầu tiên nhằm phát triển mô hình.
- Kiến trúc data-centric đề cập đến một hệ thống trong đó dữ liệu là nguồn tài nguyên chính và lâu dài, trong khi các ứng dụng khác có thể thay đổi.
- Kiến trúc data-driven có nghĩa là phát triển công nghệ, kỹ năng và môi trường dựa vào việc khai thác thông tin hoặc tri thức từ một lượng dữ liệu lớn.
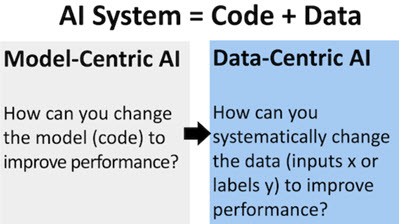
So sánh data-centric và model-centric
Hiện nay, cách tiếp cận model-centric đang phổ biến hơn đối với các nhà khoa học dữ liệu và kỹ sư học máy. Tuy nhiên, một khi dữ liệu không được quan tâm đúng mức, đội ngũ phát triển có thể lãng phí hàng trăm giờ để tinh chỉnh một mô hình dựa trên dữ liệu lỗi. Đây cũng là nguyên nhân cơ bản khiến mô hình có độ chính xác thấp và không được tối ưu hóa.
| Model-centric Machine learning | Data-centric Machine learning |
| Chủ yếu làm việc trên code | Chủ yếu làm việc trên dữ liệu |
| Tối ưu hóa mô hình để xử lý tốt dữ liệu nhiễu | Không chỉ thu thập nhiều dữ liệu hơn, mà còn tập trung cải tiến chất lượng để xử lý dữ liệu nhiễu |
| Nhãn dữ liệu thiếu nhất quán | Dữ liệu nhất quán |
| Dữ liệu được giữ cố định sau khi chuẩn hóa | Code/thuật toán được giữ cố định |
| Mô hình được cải thiện | Chất lượng dữ liệu được cải thiện |
Tuy nhiên, không nhất thiết phải tập trung hoàn toàn vào dữ liệu, đôi khi việc cải thiện code/mô hình cũng rất quan trọng vì bản chất của mô hình là phản ánh và khái quát hóa thông tin bên trong dữ liệu. Cách tốt nhất là kết hợp cả hai phương pháp model-centric và data-centric, tùy thuộc vào bài toán và ứng dụng mà bạn đang triển khai.
Thực tế, quy trình làm việc tập trung vào mô hình phù hợp với một số ngành, chẳng hạn như truyền thông và quảng cáo, nhưng khi ứng dụng trong các ngành chăm sóc sức khỏe hoặc sản xuất, nó sẽ gặp phải một số thách thức về khả năng tùy chỉnh cũng như yêu cầu các bộ dữ liệu quy mô lớn. Khi ứng dụng phương pháp data-centric, cần lưu ý đến:
- Chất lượng dán nhãn dữ liệu: nhãn cần cung cấp đầy đủ thông tin về nội dung và cấu trúc của tập dữ liệu, với các yếu tố như loại dữ liệu, đơn vị đo lường và khoảng thời gian. Cách tốt nhất để cải thiện chất lượng nhãn là tìm ra điểm không nhất quán trong nhãn và làm theo hướng dẫn gán nhãn.
- Tăng cường dữ liệu (data augmentation): Được sử dụng để tự động tạo thêm dữ liệu huấn luyện cho các mô hình học máy thông qua các phương pháp nội suy hoặc ngoại suy. Ví dụ, các kỹ thuật này có thể được dùng để tổng hợp các ảnh hoặc khung video theo nhiều mức độ xuất hiện trong thực tế. Các phương pháp này giúp làm giàu dữ liệu huấn luyện. Tuy nhiên bổ sung dữ liệu không phải lúc nào cũng là lựa chọn tốt nhất. Việc đưa thêm vào các mẫu dữ liệu nhiễu có thể làm giảm tính tổng quát hóa của mô hình.
- Kỹ thuật xây dựng thuộc tính cho mô hình (feature engineering): là quá trình thêm các thuộc tính vào mô hình bằng cách thay đổi dữ liệu đầu vào, tri thức nền hoặc thuật toán. Nó được sử dụng trong học máy để giúp tăng độ chính xác của mô hình dự đoán.
- Lập phiên bản dữ liệu (data versioning): Việc quản lý quyền truy cập tập dữ liệu, cũng như nhiều phiên bản của mỗi tập dữ liệu là rất khó khăn và dễ xảy ra lỗi. Lập phiên bản dữ liệu là một trong những bước không thể thiếu để duy trì dữ liệu, giúp theo dõi các thay đổi (cả bổ sung và xóa) đối với tập dữ liệu.
- Tri thức ngành: Tri thức ngành rất có giá trị trong cách tiếp cận lấy dữ liệu làm trung tâm, giúp tăng cường hiệu quả hoạt động của mô hình học máy. Các chuyên gia trong lĩnh vực hẹp thường có thể phát hiện ra sự khác biệt nhỏ mà các kỹ sư học máy, nhà khoa học dữ liệu và đội ngũ dán nhãn không thể.
Đặc biệt, một ghi chú nhỏ: Nhiều hơn không có nghĩa là đương nhiên tốt hơn, điều này đúng với dữ liệu (more data does not automatically equal better data). Tuy nhiên, hãy đảm bảo có đủ dữ liệu để giải quyết bài toán, nhất là những bài toán về Deep Networks. Theo Yolo 5 gợi ý, cần tối thiểu 1 500 hình ảnh và tổng số tối thiểu 10 000 đối tượng được dán nhãn cho mỗi lớp. Nếu bạn đang tìm kiếm các bộ dữ liệu có chất lượng thì có thể tham khảo Kaggle, Datahub.io hoặc Graviti Open Datasets.